Predicting Income and Gender with Census Data
In this project we try to predict income and gender using US Census Data. We will use classification models to try to predict both variables.
Before we try out the different classification models there was some data exploration and processing that had to occur first:
1 - Since income data was a numerical variable, we changed it to a categorical variable where the income was either <= 50k or >50k.
2 - We deal with missing and duplicate values
3 - Removal of outliers
4 - Correlation between features
5 - One-hot-encoding categorical variables
6 - Splitting data into training and test Data
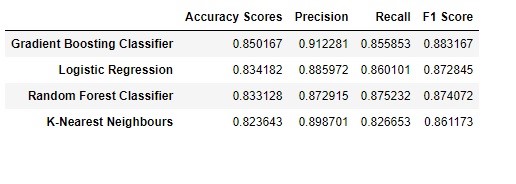
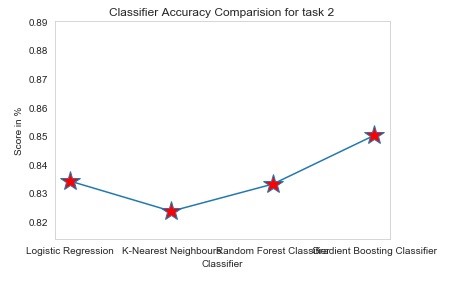
After that is done we start to run and evaluate models with the following metrics:
1 - Accuracy
2 - Precision/Recall
3 - F-1 Score
The different models that are used in this project were:
1 - Support Vector Machines
2 - K-Nearest neighbors
3 - Random forest
4 - Gradient Boosting
5 - Logistic Regression
We were able to create prediction models for income and gender with over an 85% accuracy. Gradient boosting came out as the best working model for both cases.
Later in the project we looked over feature importance within the Census data and then did a GridSearch for each of the types of models to determine the best parameters before running the actual models. The complete workbook can be found within the Github link
- census
- gender
- income
- support vector
- k-nearest neighbors
- random forest
- gradient boost
- logistic regression